Documentation for Overton's REST API
Overton has a simple REST based API that returns data in JSON format, allowing you to access everything in our database programmatically.
This documentation covers how to use the API - how we collect the data, what it represents and its caveats and biases are documented in more detail on our help pages.
These pages are a work in progress and will be updated regularly. If you have any questions or feedback then please do contact us at support@overton.io.
Quickstart
Before you jump in please note that:
- You'll need an API key
- You should not call the API more than once a second - if you do, you'll be blocked and rate limited
- The API is intended for system integration, targeted requests and ad hoc queries. For larger analysis projects or if you're trying to get a lot of data quickly the data snapshots may be a better option
The quickest way to get started is to generate an API query inside the Overton app. Look for the “Generate API call” option inside the “Export” menu, in the grey action bar above your search results:
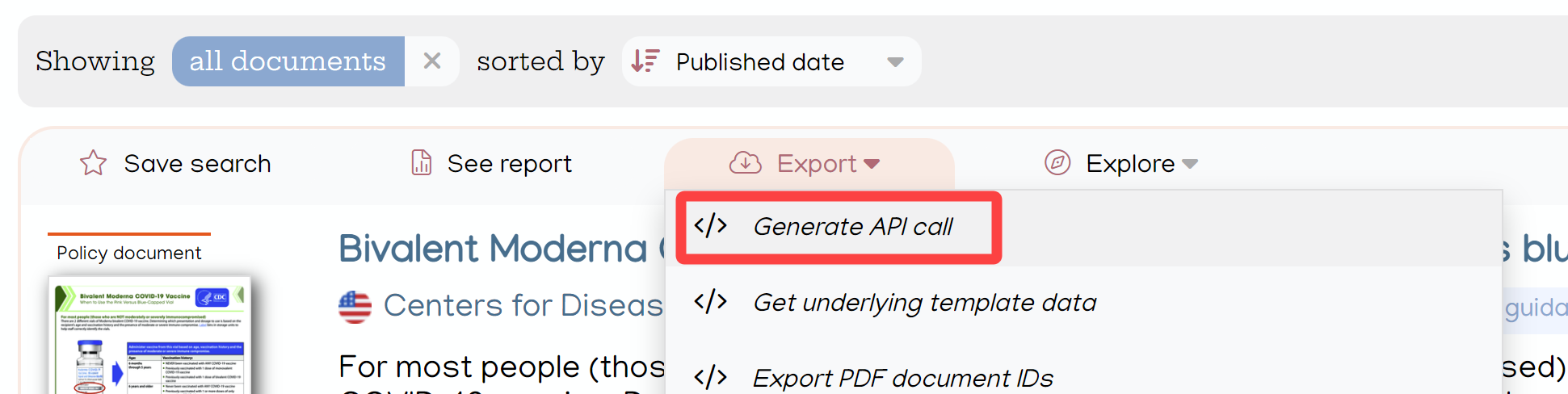
The URL that you're redirected to is a valid API call and uses your personal API key.
Note that API access isn't enabled by default on all accounts; if you don't see the “Generate API call” menu option then contact your account manager or the support team at support@overton.io to request access.
Authenticating
All calls to the API need to contain an api_key parameter in the URL
containing your personal API key. Each Overton user has exactly one API key, and they can only be
revoked by support: account wide API keys (e.g a shared key for a specific script or product at a
university) don't exist.
The easiest way to find your API key is to generate a call from the app (as above) and look for the api_key parameter in the URL.
Bear in mind that the API key will be visible to anybody who can see the source code of your app, so avoid making calls from client-side code (e.g. JavaScript in a browser) unless you're sure you can keep the key secret.
Interpreting results
The API results are generally broken up into three sections.The query
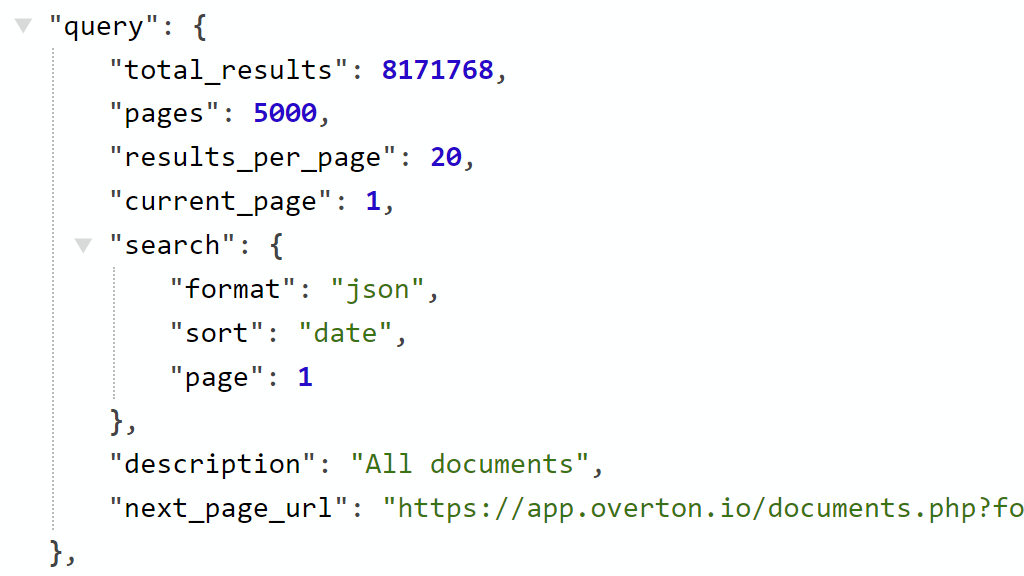
The query object tells you the total number of results returned for your query, and the number of pages that can be returned for the search (note that you may have a page limit on your account).
To select a page use the &page=x parameter, where x is a valid page
number.
Facets

The Facets key contains roll-up information for various fields – this is what is displayed in the left hand sidebar on Overton’s search pages.
Results
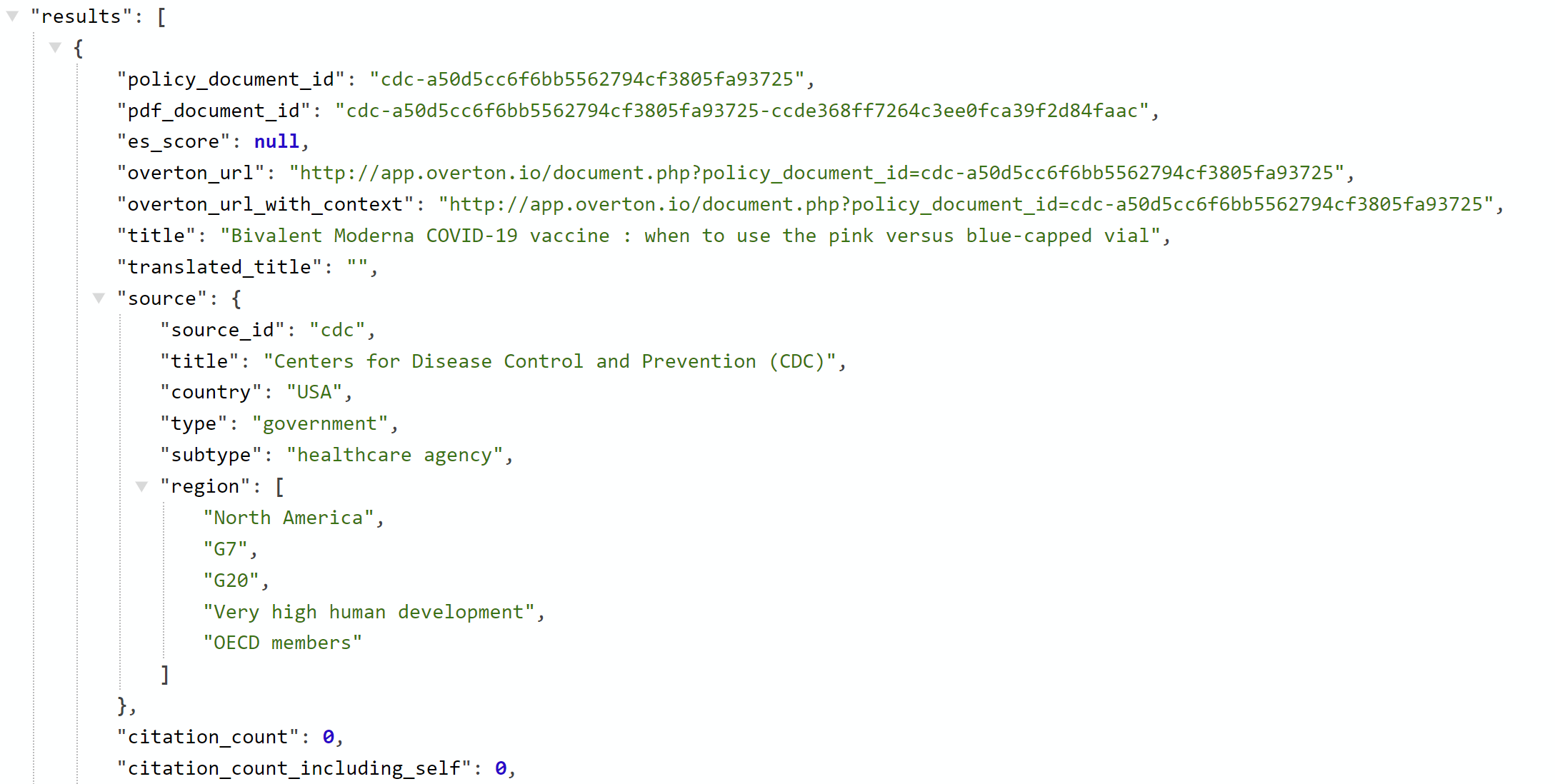
The Results key contains the actual results of your query.
When you're looking at scholarly articles then we use doi as a unique ID -
this is the article's DOI from CrossRef or similar
agencies.
Each policy document has two IDs - the pdf_document_id and the policy_document_id. The pdf_document_id is the
ID of the PDF that we've extracted the text from, and the policy_document_id
is the ID of the policy document itself. A single policy document may contain multiple PDFs.
Rate Limiting
Please call the API no more than once a second. Rate limiting is enforced but with leeway: if you accidentally go faster than this for a little while it's fine but if you push up against the limits too frequently then your API key may be blocked automatically.
If you are rate limited then you'll see a 429 HTTP status code and empty results come back from the API.
Common questions
How do I paginate through the results?
The page parameter allows you to paginate through results.
Some endpoints also have a next_page_url parameter inside the query block that increments the page number for you automatically, making
it easy to paginate through results. If a result set has no next_page_url
set then you've reached the end of the results.
What's the difference between policy_document_id and pdf_document_id?
In Overton every policy document object is made up of one or more PDF objects.
Imagine a publication landing page representing a report on a government website.
Even though it's all related to the one report that landing page may link out to a number of different documents:
- An executive summary
- The actual report
- An appendix containing tables and figures
We'd represent this as three PDFs (each with their own pdf_document_id)
grouped into one document (with a single policy_document_id).
You can read more about this on our help pages.
Can I use the thumbnails produced for each document?
Yes, but please cache them locally and don't hotlink to them. We may change the URLs of the thumbnails in the future and we don't want to accidentally break your site.
Where's the full text?
For licensing reasons the API does not include full text content of PDFs: to obtain this you must use the pdf_url field and fetch and process the relevant PDF yourself. For some documents pdf_url is not present, or is the same as the document_url: these are policy documents that are only available in HTML and so data must be scraped from there.
Examples
Get a breakdown of countries for all documents matching a free text query
Let's try fetching the metadata for a set of policy documents in the system.
We'll send a search query that will search the fulltext of policy documents and then extract a list of countries (& states, where relevant) that any matching documents are from.
The request
https://app.overton.io/documents.php?query=%22climate+change%22&format=json&api_key={API_KEY}
In this example, the parameters are:
- A text query of "climate change", in the
queryparameter - JSON format specified in the
formatparameter - A valid API Key specified in the
api_keyparameter
What to expect
The results of this request will be policy documents, but we're going to ignore them in this example.
The facets section will contain metadata about those documents. We're interested in the countries that the results are from, we'll find this in the policy_source_country key. The countries will already be ordered by the number of results (i.e. policy documents) associated with them in the results set.
Parsing the response
Run the query, and look in the facets section. Each country listed in the policy_source_country array there will have a name and a doc count - this is the number of policy documents from that country.
You don't need to paginate through the results for this request. The facets section always contains metadata about all of the results in your query, not just the ones on the current page.
The response
The response for this request will look something like:
query: {
total_results: 454144,
pages: 5000,
results_per_page: 20,
current_page: 1,
search: {
query: ""climate change"",
format: "json",
sort: "relevance",
page: 1
},
description: "Documents matching the query '"climate change"'",
next_page_url: "https://app.overton.io/documents.php?query=%22climate+change%22[..]&page=2"
},
facets: {
...
policy_source_country: [
{
key: "USA",
doc_count: 109284
},
{
key: "Canada",
doc_count: 28424
},
...
],
...
},
results: [ ... ]
Get all of the policy documents that cite a given DOI
Given a DOI, let's retrieve all of the policy documents that cite it.
The request
https://app.overton.io/documents.php?plain_dois_cited=10.1086/669786&format=json&api_key={API_KEY}
In this example, the parameters are:
- The DOI we're interested in (10.1086/669786), in the
plain_dois_citedparameter - JSON format specified in the
formatparameter - A valid API Key specified in the
api_keyparameter
What to expect
The results of the request will be any policy documents that cite the given DOI (10.1086/669786).
The facets section will contain metadata about those documents, but we're going to ignore these in this example.
The query section will contain information about the results, including the total number of results, the number of pages that can be returned and the URL to call to get the next page of results if appropriate.
Parsing the response
The results key will contain an array of results from the current page. Each result will contain a policy_document_id and a pdf_document_id - these are unique identifiers for each document.
You can find the title of the document in the title key (in the example below, "Deterrence or Backlash?"), and information about the source of the document (in the example below, the IZA think tank in Germany) in the source key.
Once you've looped through the results on this page, look in the query section for the next_page_url key. If this is present then you can call that URL to get the next page of results.
The response
The response for this request will look something like:
{
query: {
total_results: 34,
pages: 2,
results_per_page: 20,
current_page: 1,
search: {
plain_dois_cited: "10.1086/669786",
format: "json",
sort: "date",
page: 1
},
description: "Documents citing the given DOI(s)",
next_page_url: "https://app.overton.io/documents.php?plain_dois_cited=10.1086%2F669786&[..]&page=2"
},
facets: { ... },
results: [
{
policy_document_id: "ifode-4ee1572bb0c754587123cc391e804b29",
pdf_document_id: "ifode-4ee1572bb0c754587123cc391e804b29-a9d98e053730f6c004e7c67b439aaa30",
title: "Deterrence or Backlash?",
translated_title: "",
source: {
source_id: "izade",
title: "IZA Institute of Labor Economics",
country: "Germany",
type: "think tank"
},
...
},
...
]
}
Generate a set for multiple identifiers
Sometimes, you may have a large list of document identifiers (DOIs for documents and articles, or ISBNs, ORCIDs or PMIDs for articles), and want to populate one of the search fields with this list. Adding a large number of identifiers can be unwieldy and error-prone.
In this scenario, we recommend generating a set for your list of identifiers, which can then be used in place of the individual identifiers when searching
The request
Unlike the other examples on this page, this request will be a POST request.
POST https://app.overton.io/generate_id_set.php?format=json&api_key={API_KEY}
Content-Type: application/x-www-form-urlencoded
dois = 10.1007/s11557-024-01957-1
10.1080/22221751.2024.2321993
In this example, the parameters are:
- JSON format specified in the
formatparameter - A valid API Key specified in the
api_keyparameter - A list of identifiers, each on their own line in the
doisparameter of the body
The response
The response for this request will look something like:
{
"set": "set:1:b4db3419c889561a69767498f6727a0f"
}
What to expect
The response will contain the generated ID for the set in the set_id key.
If there are any warnings about the identifier provided, they will be in the warnings key, alongside the set ID
If there are any errors, they will be in the error key, and no set ID will be returned
How to use this
The set ID can be used in place of the individual identifiers when searching. For example, the request in the previous section was:
https://app.overton.io/documents.php?plain_dois_cited=10.1086/669786&format=json&api_key={API_KEY}
and in order to use a set in this example, the request would become:
https://app.overton.io/documents.php?plain_dois_cited=set:1:b4db3419c889561a69767498f6727a0f&format=json&api_key={API_KEY}